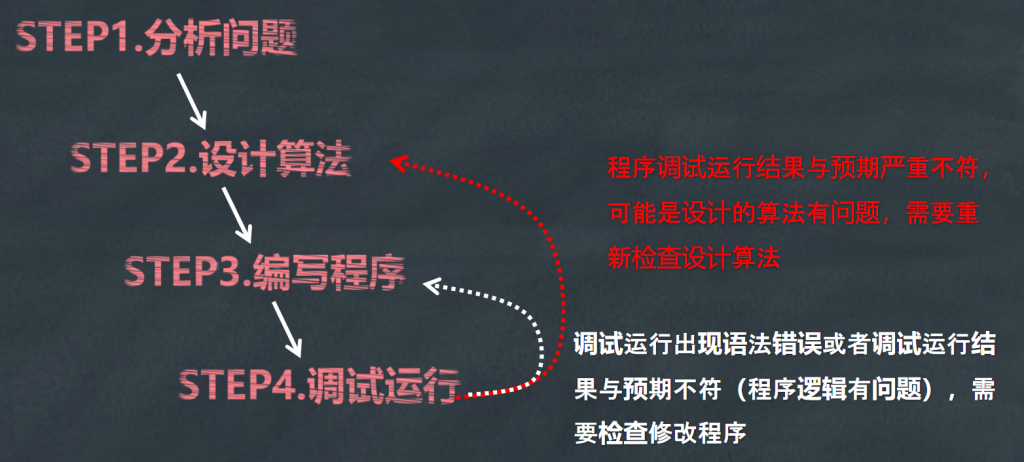
近年来,编程的重要性已成为越来越多的国际意识的主题,从“极客”的狭隘领域扩展到包括K-12教育领域在内的更广阔的世界。从美国在学校强制推行计算机程序设计教育,到全球范围内兴起“每天编程一小时”活动,再到我国教育部公布《2019年教育信息化和网络安全工作要点》,其中指出:今年将启动中小学生信息素养测评,并推动在中小学阶段设置人工智能相关课程,逐步推广编程教育。对于我们普通人来说,编程的能力也正在凸显出前所未有的重要性。
在琳达·卢卡斯的演讲中,她认为“编程就是一个表达自我的方式”。当她了解到,父母可以很轻松的向孩子解释人体的生理构造如何运作,却无法回答关于电脑如何运作的问题。因为不少人也对计算机不够了解,他们“离开精美的用户界面后就不知道如何与计算机交流”。但是演讲者告诉大家,计算机科学并非深奥难懂的学科,反而生活中处处有计算机科学。
教育部于2017年底正式公布了《普通高中信息技术课程标准(2017年版)》,新的课程标准将原来从知识与技能、过程与方法、情感态度与价值观三个维度描述的目标进行了整合,凝练为信息技术学科的四大核心素养:信息意识、计算思维、数字化学习与创新、信息社会责任。计算思维是计算机科学领域的思想方法,是学科本质的体现,是形成问题解决方案的过程中产生的一系列思维活动。
学科核心大概念是学科知识体系的关键核心,有别于学科核心素养指向人的能力、品格与价值观,核心大概念指向知识结构本身。新课程标准明确指出了信息技术学科的四个核心大概念,分别是数据、算法、信息系统、信息社会。其中算法是对特定问题求解步骤的一种描述,是一系列解决问题的清晰指令,精确的算法是计算工具有效计算的前提条件,也是编程的具体指导方法。由此可见,算法指导下的编程是借助计算思维解决问题的一种重要手段。
编程不经意间变得流行起来。越来越多的人发现学会编程是必不可少的,尤其是对年轻一代来说。在一个借助互联网在几毫秒内搜索任何问题答案的世界中,对于学生来说必备的技能不再仅限于传统知识的学习能力。有很多能让人成功的技巧,而这套技能必须包括编程。
一、编程是数字时代的基本素养

当今是一个技术日新月异的时代,要适应这个时代,首先需要知道如何使用这些技术。而要更好地使用这些技术,还需要了解技术背后的逻辑。学习编程时,我们能够理解并摆弄自己所居住的数字世界。编程使技术看起来更像是“魔法”,我们就能够真正理解并控制这项技术的逻辑——只有这样这一过程才更具有魔力。
我们对技术的依赖只会增加。今天的青年一代不仅仅是能够被动地使用新技术,而且要能够理解和控制它,成为这个巨大数字转变的积极组成部分。
二、编程可以改变世界
我们已经看到生活中编程的成果正在改变世界。当互联网开始将当代人的生活由“日用品"变成“必需品",越来越多的人意识到“编程可以改变世界"。编程是最直接的智力高质转换。通过编程计算机语言,一个人在棋牌等娱乐竞技中体现出的智慧也能够转化为具有实际应用价值和产业价值的输出。
编程是为了自己的世界,可以构造和完善自己的世界。AI时代的编程,拥有大量的接口和配件,我们可以根据自己的想象来构建和完善自己的世界。有的编程语言是为了改变世界,所以它复杂而庞大,有的编程语言是为了改变生活,所以我们的编程工作简约而又优美。我们可以制作各种小家电,可以编程实现各种小应用工具,还可以编程丰富娱乐生活。
三、借助编程让创新想法落地
“你为下一个巨大创新有一个想法?太棒了!你怎么落地?”。每个人都有想法,只有少数人能付诸实践让创意成为现实。编程的能力将那些只有想法的人与能把想法付诸实践的人分开。
目前风靡全球的创客运动,就是鼓励人们将个人的想法积极付诸实践。而在实践的过程中不经意就会涉及大量综合学科内容,其中编程往往不可缺少,也是重要的工具。
如果你想成为一个能给生活带来灵感的思考者和创新者,鼓励自己并加入到学习编程的队伍中来吧。编程让你相信自己可以成为设计师和建设者。
四、编程更是对思维的训练
乔布斯说:“每个人都应该花一点时间学习编程,因为一个学过编程的人,他有一种独特的角度去思考世界”。
任何一个程序中都不是相互分割无关的数据组成,相反,一个程序中会存在很多“重复”内容。比如,贪吃蛇中的“吃食物”动作,一个游戏中贪吃蛇会吃到很多次食物,这也就是前面说到的“重复”。编程过程中,我们需要一直做这样的训练,发现程序中会一直持续的动作,然后将它打包起来,让计算机自己重复,以提高编写效率。学会利用这一点,我们就能学会整合讯息的能力。整合并不是简单相加,而是对现状的优化,也是推陈出新的方式之一。
其实编程也是一种语言的学习,只不过和人与人之间沟通不同的是,这种语言是人与计算机的沟通。理性、严谨是计算机的特性,所以与它对话的语言也必须是理性的,严谨的,不能出半点偏差的。"较真",是外界对程序员们的评价,也是每一个程序员所遵守的信念。仍旧以贪吃蛇游戏程序为例,如果某处思考出现漏洞,游戏过程中就可能会出现“贪吃蛇撞了墙没死”或者“贪吃蛇吃到食物没有变大”等bug,那么这就是一个失败的程序。因此,学习编程,就是在对自己的逻辑思维和逻辑判断能力进行训练。
人的一生不可能不犯错。其实犯错也没什么,改了就好。而“改正”就是编程带给我们的逻辑能力中最重要的一项。但凡程序中出现与预期不一样的运行结果,都需要进行调试、修正。这个过程很麻烦,因为有些bug不是一下子就能找到的,常常需要从头梳理,十分考验人的耐心和细心程度。不过也正因此,才更能磨练出个人的品性,同时也能教会我们反思反省意识。
五、信息学竞赛对升学的帮助

2019年伊始,教育部发布了《关于做好2019年高校自主招生工作的通知》,提出了规范自主招生的“十严格”要求。文件中再次强调:降低自招优惠分值,降低自招优惠人数规模;论文、专利、机构的“假奖项”不得作为条件。导致的后果是文科类竞赛在自主招生中彻底出局,科创类竞赛含金量大幅缩水,学科竞赛类一家独大。
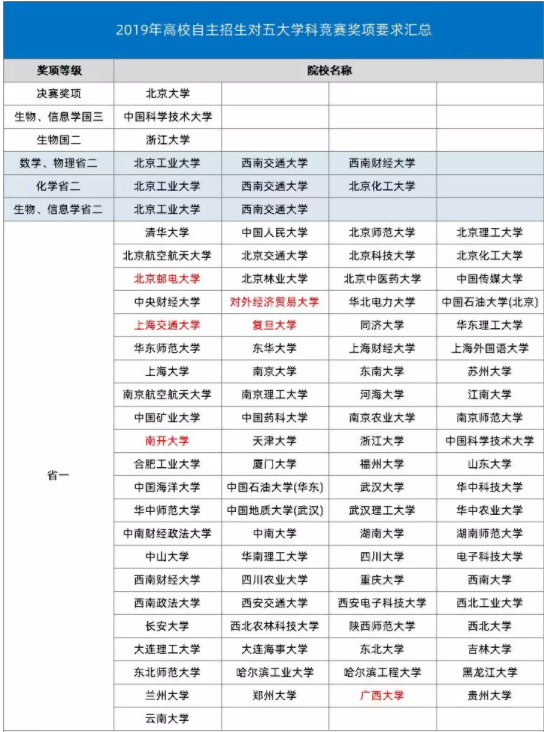
2019年《国务院办公厅关于新时代推进普通高中育人方式改革的指导意见》要求稳步推进高校招生改革。进一步健全分类考试、综合评价、多元录取的高校招生机制,逐步改变单纯以考试成绩评价录取学生的倾向。这就意味着综合评价政策在未来会成为多元录取的主要形式。但是从2019年采用综合评价的省市招生情况来看,学科竞赛依然是热门。
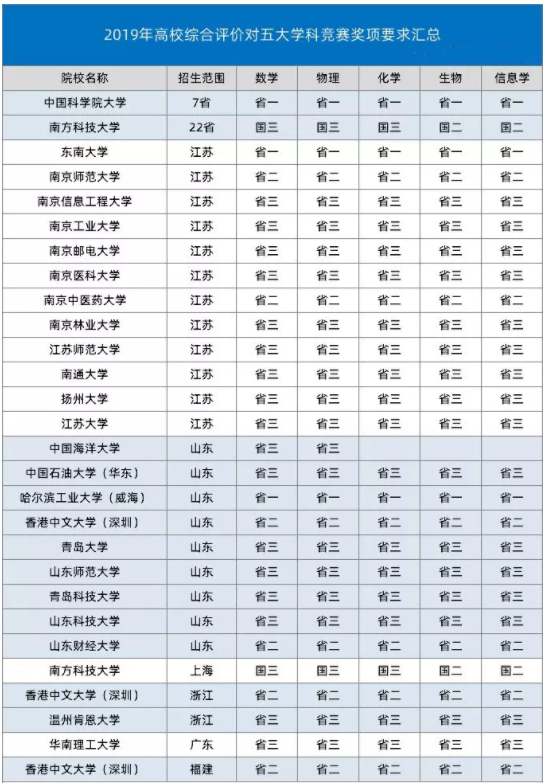
信息学竞赛是五大学科竞赛(数学、物理、化学、生物、信息学)之一,在信息学竞赛中获得奖励,对于当前自主招生和综合评价政策形式下的升学有很大帮助,至少是一块“敲门砖”。而信息学竞赛注重的更是思维的训练,编程只是解决问题的想法落地的工具!
中国计算机学会(CCF)于1984年创办全国青少年计算机程序设计竞赛(NOI),从此每年一次NOI活动,吸引越来越多的青少年投身其中。几十年来,通过竞赛活动培养和发现了大批计算机爱好者,选拔出了许多优秀的计算机后备人才。当年的许多选手已成为计算机硕士、博士,有的已经走上计算机科研岗位。
为了在更高层次上推动普及,培养更多的计算机技术优秀人才。竞赛及相关活动遵循开放性原则,任何有条件和兴趣的学校和个人,都可以在业余时间自愿参加。 NOI系列活动包括:全国青少年信息学奥林匹克竞赛和全国青少年信息学奥林匹克网上同步赛、全国青少年信息学奥林匹克联赛(NOIP)、冬令营、选拔赛和出国参加 IOI。
CSP-J/S:CCF非专业级软件能力认证(Certified Software Professional Junior/Senior,简称CSP-J/S)创办于2019年,是由CCF统一组织的评价计算机非专业人士算法和编程能力的活动。全国统一大纲、统一认证题目,任何人均可报名参加。CSP-J/S分两个级别进行,分别为CSP-J(入门级,Junior)和CSP-S(提高级,Senior),两个级别难度不同,均涉及算法和编程。CSP-J/S分第一轮和第二轮两个阶段。第一轮考察通用和实用的计算机科学知识,以笔试为主,部分省市以机试方式认证。第二轮为程序设计,须在计算机上调试完成。第一轮认证成绩优异者进入第二轮认证,第二轮认证结束后,CCF将根据CSP-J/S各组的认证成绩和给定的分数线,颁发认证证书。CSP-J/S成绩优异者,可参加NOI省级选拔,省级选拔成绩优异者可参加NOI。
NOIP:全国青少年信息学奥林匹克联赛(National Olympiad in Informatics in Provinces简称NOIP)自1995年至今。每年由中国计算机学会统一组织。 NOIP在 同一时间、不同地点以各省市为单位由特派员组织。全国统一大纲、统一试卷。初、高中或其他中等专业学校的学生可报名参加联赛。联赛分初赛和复赛 两个阶段。初赛考察通用和实用的计算机科学知识,以笔试为主。复赛为程序设计,须在计算机上调试完成。参加初赛者须达到一定分数线后才有资格参加复赛。联赛分普及组和提高组两个组别,难度不同,分别面向初中和高中阶段的学生。
六、编程并不难学
事实上,编程是一个简单的过程。编程的一个最重要的特点是,它提供了即时的反馈(编写代码运行就能马上看到效果),这是学习编程的关键。如果我们编写程序解决了一个问题,然后立即看到自己想要的结果,这样我们就已经知道自己正确地操作了程序代码。这种即时的正面强化是一种令人难以置信的强大工具。
学习如何编程就像学习其他语言一样,必须练习和测试技能。正如语言打开了人与人交流的能力,编程使我们有能力创造影响周围人的技术。只要有一台普通的电脑,我们就可以利用编程技巧来构建能够改变世界的东西。
如果你还没学习如何编程,现在是时候开始了!
七、几个程序(竞赛)网站
- NOI官网:http://www.noi.cn/
- 中国计算机学会:https://www.ccf.org.cn/
- 块语言编程游戏:https://playground.17coding.net/
- 洛谷:https://www.luogu.com.cn/
八、推荐学习书籍
信息学竞赛对于编程语言的大篇幅学习仅限于初期,后期主要内容是数据结构和算法。因此强烈不建议使用侧重编程语言系统全面学习的书籍(例如《C++从入门到精通》、《C++ Primer》),也不推荐不加甄别地通过网络教程学习(绝大多数网络教程同样偏重于编程语言的学习,并且有大量生僻对于竞赛不实用的内容)。这里推荐几本适合竞赛入门的学习书籍:
- 《信息学竞赛一本通》(第五版 C++版)
- 《深入浅出程序设计竞赛》(洛谷学术组)
- 《CCF中学生计算机程序设计》入门篇、基础篇、提高篇
- 《算法竞赛入门经典》与配套的《算法竞赛入门经典训练指导》