一、映射简介
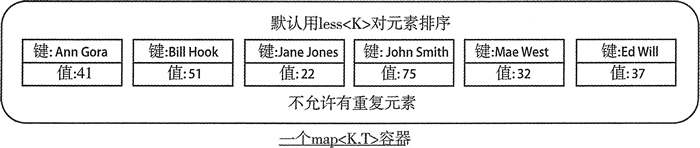
map,提供一种“键—值”关系的一对一(键值对)的数据存储能力。这里的一对一关系,其中第一个可以称为关键字,第二个可能称为该关键字的值。其“键”在 map 容器中是唯一,且按一定顺序排列(可以将 set 也看成是一种简单“键—值”关系的存储,只是它只有键没有值。set 是 map 的一种特殊形式)。
map 用于保存“键—值”关系的数据,而这种键值关系采用了类数组的方式。数组是用数字类型的下标来索引元素的位置,而 map 可以用更多数据类型的关键字来索引元素的位置,例如字符串 string,甚至是结构体。例如数组第 0 个元素可以使用 a[0] 来取值赋值,map 也可以用这样的下标方式来取值赋值,例如 m["Jerry"]。
multimap 和 map 的原理基本相似,不过它允许“键”在容器中可以不唯一。
二、为什么用map
先来看一个简单的例子,要存储一个班级所有同学的学号和姓名信息,每位同学的学号是唯一的,并且要提供根据学号查询姓名的功能。简单地,可以用两个数组来存储所有同学的学号和姓名,存储时保证同一个同学的学号和姓名存在两个数组的同一个位置(同一个下标)即可:
#include<iostream>
#include<string>
using namespace std;
const int N = 110;
//同学的学号和姓名,分别存到两个string数组中,要求一一对应
string ids[N],names[N];
int main(){
int n;
cin>>n;
//存储学号和姓名
for(int i=1;i<=n;i++){
string id,name;
cin>>id>>name;
ids[i] = id;
names[i] = name;
}
//输出学号信息对应信息
for(int i=1;i<=n;i++){
cout<<ids[i]<<" -> "<<names[i]<<endl;
}
//通过学号查找姓名
string lookid;
cin>>lookid;
bool flag = 0;
for(int i=1;i<=n;i++){
if(ids[i]==lookid){
cout<<ids[i]<<" -> "<<names[i]<<endl;
flag = 1;
break;
}
}
if(!flag) cout<<"Not Found!"<<endl;
return 0;
}
当然也可以使用结构体 vector 来存储和查询,但这两种方式查询的效率不高:
#include<iostream>
#include<string>
#include<vector>
using namespace std;
struct Student{
string id,name;
Student(string id,string name){
this->id = id;
this->name = name;
}
};
int main(){
vector<Student> ve;
int n;
cin>>n;
//存储学号和姓名
for(int i=1;i<=n;i++){
string id,name;
cin>>id>>name;
ve.push_back(Student(id,name));
}
//输出学号信息对应信息
for(auto it=ve.begin();it!=ve.end();it++){
cout<<(it->id)<<" -> "<<(it->name)<<endl;
}
//通过学号查找姓名
string lookid;
cin>>lookid;
auto it=ve.begin();
for(;it!=ve.end();it++){
if(it->id==lookid){
cout<<(it->id)<<" -> "<<(it->name)<<endl;
break;
}
}
if(it==ve.end()) cout<<"Not Found!"<<endl;
return 0;
}
来看看使用 map 的处理方法:
#include<iostream>
#include<string>
#include<map>
using namespace std;
int main(){
//申明键类型为string,值类型为string的map
map<string,string> m;
int n;
cin>>n;
//存储学号和姓名
for(int i=1;i<=n;i++){
string id,name;
cin>>id>>name;
//类似于数组下标访问赋值的方式,建立“学号-姓名”键值对
m[id] = name;
}
//遍历map
map<string,string>::iterator it = m.begin();
for(;it!=m.end();it++){
//map迭代器是一个pair指针,first成员是键,second成员是值
cout<<(it->first)<<" -> "<<(it->second)<<endl;
}
cout<<endl;
//通过学号查找姓名
string lookid;
cin>>lookid;
if(m.count(lookid)) //键lookid出现次数不为0
//类似于数组下标访问的方式,m[lookid]通过键获取对应的值
cout<<lookid<<" -> "<<m[lookid]<<endl;
else
cout<<"Not Found!"<<endl;
return 0;
}
上面的程序用 map 建立了所有同学“学号-姓名”的键值对应关系。通过 map[键]=值; 这样的赋值语句建立起一个键值对应关系,通过 map[键] 来获取键对应的值,会发现这里的操作和数组、vector 的[]操作完全相同,不过这里的键是 string 类型,下标[]中的数据类型是 string。其实这里不仅仅是程序代码更加简洁,map 内部的处理机制还使得这样的查询效率比起前面的顺序查找更快。
运行上面的程序,输入下面的数据,输出结果如下:
输入样例:
6 1101 Jerry 1103 Jack 1102 Tom 1104 Lucy 1106 Zoe 1105 Lily 1106
输出样例:
1101 -> Jerry 1102 -> Tom 1103 -> Jack 1104 -> Lucy 1105 -> Lily 1106 -> Zoe 1106 -> Zoe
程序处理过程中,建立了“学号-姓名”的键值对应关系,可以简单认为 map 就是维护了类似于下面这样的一张表格(由于 map 内部数据是按照键升序排列的,所以实际存储方式是右侧的形式),通过键就能找到对应的值:
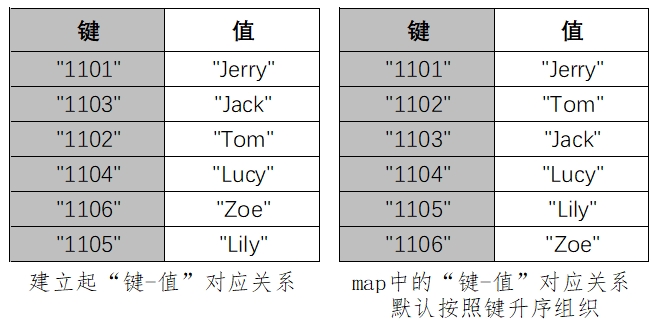
实际存储时键并不是像上面的表格那样顺序存储,而是采用高效的红黑树的平衡二叉树,所以 map 的查询效率比起数组和 vector 的顺序查询效率高。
三、map的使用
map 的使用方法和 set 相似,set 就相当于只有键没有值的 map。
1.定义map变量
要使用 map 或者 multimap,首先要引入 map 头文件:#include<map>。简单地申明映射时,映射中的键默认是按照从小到大排列(less<T>)的,当然可以指定排序规则:
//键string类型,值int类型 map<string,int> m1; //键string类型,值string类型 map<string,string> m2; //键string类型,值vector<int>类型 map<string,vector<int> > m3; //键int类型,值Student类型 map<int,Student> m4; //键int类型,值string类型,键按照greater<int>组织 map<int,string,greater<int> >m5; //键string类型,值string类型,键按照less<string>组织 map<string,string,less<string> >m6;
与 set 相同,map 中的键甚至可以是结构体或者类,不过要通过比较函数或者重载运算符的方式来确定键在 map 内部的排序形式。
#include<iostream>
#include<map>
using namespace std;
struct Student{
string id,name;
};
struct Score{
int yw,sx,yy;
};
//通过结构体自定义类似于less<T>和greater<T>的仿函数
struct cmp{
bool operator ()(const Student &a,const Student &b){
return a.id<b.id;
}
};
int main()
{
//键Student类型,值Score类型,键按照仿函数cmp组织
map<Student,Score,cmp > m;
//存储一个键值对信息
m[Student{"1101","Jerry"}] = Score{120,145,138}; //使用高版本C++初始化结构体语法
return 0;
}
2.插入、修改与获取元素
前面已经看到可以通过[]的方式建立键值对,或者通过键获取值:m[键]=值;、cout<<m[键];
通过索引的方式设置键值对,如果键不存在则会新创建键值对,如果键存在则会更新键对应的值;
map<string,string> m; m["1101"] = "Jerry"; //键不存在,新创建键值对 cout<<m["1101"]<<endl; m["1101"] = "Tom"; //键已存在,更新键对应值 cout<<m["1101"]<<endl;
还可以通过成员函数 insert 插入 pair 的方式建立键值对,例如:
map<string,string> m;
m["1101"] = "Jerry";
m.insert(make_pair("1102","Jack"));
m.insert(map<string,string>::value_type("1103","Tom"));
insert 插入元素与 m[键]=值; 有细微的差别:如果键已经存在,insert 不会执行任何操作,返回值会带有标识插入失败的信息;m[键]=值;则会修改已有键值对的值。
#include<iostream>
#include<string>
#include<map>
using namespace std;
int main(){
map<string,string> m;
m["1101"] = "Jerry";
cout<<m["1101"]<<endl;
//键"1101"已经存在,值会被修改为"Jack"
m["1101"] = "Jack";
cout<<m["1101"]<<endl; //输出Jack
//键"1101"已经存在,insert不会修改值
m.insert(make_pair("1101","Tom"));
cout<<m["1101"]<<endl; //输出Jack
return 0;
}
3.查找map的键
- count(x)返回键x出现的次数,map返回值为0或1,multimap返回值不止0和1;
- find(x)返回键为x的迭代器,如果没有找到,返回值与end()相等;
- 与set一样,map也有lower_bound、upper_bound、equal_range成员函数,用法与set相同。
map<string,string> m;
m["1101"] = "Jerry";
if(m.count("1102")) cout<<m["1102"]<<endl;
auto it = m.find("1102");
if(it!=m.end()){
cout<<(it->first)<<" -> "<<(it->second)<<endl;
}else{
cout<<"Not found!"<<endl;
}
map<string,string> m;
m["1101"] = "Jerry";
m["1102"] = "Tom";
auto it1 = m.lower_bound("1101");
if(it1!=m.end()){
cout<<(it1->first)<<" -> "<<(it1->second)<<endl;
}else{
cout<<"Not found!"<<endl;
}
auto it2 = m.upper_bound("1101");
if(it2!=m.end()){
cout<<(it2->first)<<" -> "<<(it2->second)<<endl;
}else{
cout<<"Not found!"<<endl;
}
4.删除元素
- clear()清空整个map;
- erase(x)删除键为x的键值对元素,或者删除迭代器x指向的键值对元素。
map<string,string> m;
m["1101"] = "Jerry";
cout<<m["1101"]<<endl;
m.erase("1101");
cout<<m.count("1101")<<endl;
map<string,string> m;
m["1101"] = "Jerry";
cout<<m["1101"]<<endl;
auto it = m.find("1101");
if(it!=m.end()) m.erase(it);
cout<<m.count("1101")<<endl;
map<string,string> m; m["1101"] = "Jerry"; cout<<m["1101"]<<endl; cout<<m.size()<<endl; m.clear(); cout<<m.size()<<endl; if(m.empty()) cout<<"none."<<endl;
5.遍历map
通过迭代器来遍历map,map的迭代器是一个pair指针,first成员是键,second成员是值。map同样也有对应的begin()、end()、rbegin()和rend()成员函数。
map<string,string> m;
m["1102"] = "Jerry";
m["1101"] = "Jack";
m["1104"] = "Tom";
m["1103"] = "Lucy";
//遍历map
for(auto it=m.begin();it!=m.end();it++){
//map迭代器是一个pair指针,first成员是键,second成员是值
cout<<(it->first)<<" -> "<<(it->second)<<endl;
}
//反向遍历map
for(auto rit=m.rbegin();rit!=m.rend();rit++){
//map迭代器是一个pair指针,first成员是键,second成员是值
cout<<(rit->first)<<" -> "<<(rit->second)<<endl;
}
此外,还可以借助C++语言for循环的高级用法遍历map:
#include<iostream>
#include<map>
using namespace std;
int main()
{
map<string,int> m{{"Jerry",100},{"Jack",120},{"Tom",150}};
for(auto it:m){
cout<<it.first<<":"<<it.second<<endl;
}
for(auto &it:m){ //引用方式遍历
it.second = 90; //修改it的second值,m元素值也会改变
//it.first = "haha"; //编译出错,不能修改it的first值(map的键)
}
for(auto it:m){
cout<<it.first<<":"<<it.second<<endl;
}
return 0;
}
6.unordered_map
unordered_map 是基于哈希表实现的无序关联容器,用于存储键值对(key-value),其中键是唯一的。它不维护任何顺序,平均情况下能提供 \(O(1)\) 的查找、插入和删除性能(最坏情况因哈希冲突可能退化为 \(O(n)\)),相比有序的 map(红黑树,\(O(log n)\))通常更快。使用时需为键类型提供哈希函数和相等比较(默认 hash 和 operator==)。它适合需要快速通过键查找对应值、不关心元素顺序、且能接受较高内存占用的场景,例如实现缓存、字典或频率统计。
四、典型例题
1.使用map存储学生信息
和文章开始处介绍的情况类似,不过学生信息项目更多,包括学号、姓名、性别、年龄,学号唯一。那么学号仍然作为map的键,可以将学生信息封装成一个struct作为map的值。
#include<iostream>
#include<string>
#include<map>
using namespace std;
struct Student{
string name;
char sex;
int age;
};
int main(){
map<string,Student> m;
m["1101"] = Student{"Jerry",'M',32}; //使用高版本C++初始化结构体语法
m["1103"] = Student{"Jack",'M',18};
m["1106"] = Student{"Lucy",'F',24};
m["1104"] = Student{"Zoe",'F',3};
cout<<m["1106"].name<<endl;
cout<<"ID\tName\tSex\tAge"<<endl;
for(auto it=m.begin();it!=m.end();it++){
cout<<(it->first)<<"\t"<<(it->second.name)<<"\t";
cout<<(it->second.sex)<<"\t"<<(it->second.age)<<endl;
}
return 0;
}
如果还要按照班级来组织学生信息,班级内部依然按照学号组织学生信息,那么可以以班级编号(string类型)为键,map<string,Student>为值来定义map:
#include<iostream>
#include<string>
#include<map>
using namespace std;
struct Student{
string name;
char sex;
int age;
};
int main(){
map<string,map<string,Student> > m;
m["11"]["1101"] = Student{"Jerry",'M',32};
m["11"]["1103"] = Student{"Jack",'M',18};
m["11"]["1106"] = Student{"Lucy",'F',24};
m["11"]["1104"] = Student{"Zoe",'F',3};
m["10"]["1005"] = Student{"Lily",'F',25};
m["10"]["1003"] = Student{"Tom",'M',22};
cout<<m["11"]["1106"].name<<endl;
cout<<"Class\tID\tName\tSex\tAge"<<endl;
for(auto cit=m.begin();cit!=m.end();cit++){
for(auto it=cit->second.begin();it!=cit->second.end();it++){
cout<<(cit->first)<<"\t"<<(it->first)<<"\t"<<(it->second.name);
cout<<"\t"<<(it->second.sex)<<"\t"<<(it->second.age)<<endl;
}
}
return 0;
}
2.统计单词
输入一段仅有小写字母和空格组成的一段话,规定单词以空格分隔开,统计每个单词出现的次数。
输入样例:
to be a question or not to be a question is a good question
输出样例:
a 3 be 2 good 1 is 1 not 1 or 1 question 3 to 2
【思路】建立一个map<string,int>来记录每个单词出现的次数。
#include<iostream>
#include<string>
#include<map>
using namespace std;
//单词->出现次数的键值对map
map<string,int>words;
string one;
int main()
{
while(cin>>one){
words[one]++; //单词one出现次数+1
}
//使用迭代器遍历map
for(auto iter=words.begin();iter != words.end();++iter){
cout<<iter->first<<" "<<iter->second<<endl;
}
return 0;
}
因为map的特点,输出的时候作为键的单词经过了排序。如果提出一个特殊的要求,输出统计信息时,按照原文单词出现的顺序输出单词统计信息,该如何处理呢?这个时候可以再借助一个vector来记录输入时依次出现的单词:
输入样例:
to be a question or not to be a question is a good question
输出样例:
to 2 be 2 a 3 question 3 or 1 not 1 is 1 good 1
#include<iostream>
#include<string>
#include<vector>
#include<map>
using namespace std;
//单词->出现次数的键值对map
map<string,int>words;
vector<string> vw;
string one;
int main()
{
while(cin>>one){
words[one]++; //单词one出现次数+1
//第一次出现,放入到vector中
if(words[one]==1) vw.push_back(one);
}
//使用迭代器遍历vector
for(auto iter=vw.begin();iter != vw.end();++iter){
cout<<*iter<<" "<<words[*iter]<<endl;
}
return 0;
}
现在要输出另一种统计形式,具体要求参见下面的样例:
输入样例:
to be a question or not to be a question is a good question
输出样例:
3 : a question 2 : be to 1 : good is not or
也就是按照次数从高到低输出相应次数的单词信息,相同次数的单词按字典序排序。此时仍然采用上面的方式来统计每个单词出现的次数,然后使用一个map<int,vector<string> >来将相同次数的单词装入到作为这个map值的vector<string>中。
#include<iostream>
#include<string>
#include<vector>
#include<map>
using namespace std;
//单词->出现次数的键值对map
map<string,int>words;
//次数->出现次数的单词列表的键值对map
map<int,vector<string> > counts;
string one;
int main()
{
while(cin>>one){
words[one]++; //单词one出现次数+1
}
//使用迭代器遍历map
for(auto iter=words.begin();iter != words.end();++iter){
//字典counts的键为iter->second(出现次数)的vector添加单词
counts[iter->second].push_back(iter->first);
}
//int类型作为map的key,默认按照升序排列,根据题意,这里需要逆序遍历map
for(auto riter=counts.rbegin();riter != counts.rend();++riter){
cout<< riter->first <<" : ";
//遍历输出map的值riter->second(是一个vector)中的所有单词
for(auto iter2=riter->second.begin();iter2 != riter->second.end();++iter2){
cout<< *iter2 <<" ";
}
cout<<endl;
}
return 0;
}
本题还有其他解决方法,请尝试思考理解下面的程序代码:
#include<iostream>
#include<string>
#include<set>
#include<map>
using namespace std;
//单词->出现次数的键值对map
map<string,int>words;
//次数->出现次数的单词集合的键值对map
map<int,set<string> > ans;
string one;
int main()
{
while(cin>>one){
//从作为map值的原次数set中删除
ans[words[one]].erase(one);
//作为map值的原次数set为空,从map中删除键
if(ans[words[one]].empty()) ans.erase(words[one]);
words[one]++; //单词one出现次数+1
//加入到作为map值的新次数set中
ans[words[one]].insert(one);
}
//int类型作为map的key,默认按照升序排列,根据题意,这里需要逆序遍历map
for(auto riter = ans.rbegin();riter != ans.rend();++riter){
cout<< riter->first <<" : ";
//遍历输出map的值riter->second(是一个vector)中的所有单词
for(auto iter2 = riter->second.begin();iter2 != riter->second.end();++iter2){
cout<< *iter2 <<" ";
}
cout<<endl;
}
return 0;
}
这里留一个思考题:程序中的map<int,vector<string> > counts的值是vector<string>,题目要求相同次数的单词按照从小到大的顺序输出,但是程序中并没有对每个vector<string>排序就直接输出了,其实这里是不用排序的,想想为什么?如果对于相同次数的单词,要求按照原文出现顺序输出,该如何修改程序呢?
3.【洛谷】B2112 石头剪子布
【思路一】通过复杂的if...else if语句来分类讨论所有情况(一共9种),大家可以自行编写程序;
【思路二】通过二维表格来记录结果。假定Rock,Scissors,Paper分别用0,1,2表示,那么对战结果可以用下面的表格描述:
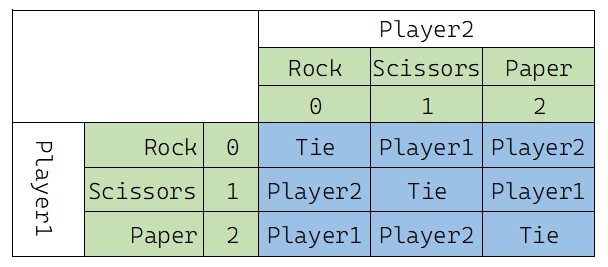
其实这个表示对战结果的表格可以用二维数组来存储:
string ans[3][3] = {
{"Tie","Player1","Player2"},
{"Player2","Tie","Player1"},
{"Player1","Player2","Tie"}
};
那么,如何将输入的字符串 Rock,Scissors,Paper 方便快捷地转换成 0,1,2 呢?用if语句太过繁琐,这里可以使用一个map<string,int>来快速转换:
map<string,int> pno; pno["Rock"] = 0; pno["Scissors"] = 1; pno["Paper"] = 2;
完整的参考程序如下:
#include<iostream>
#include<map>
using namespace std;
string ans[3][3] = {
{"Tie","Player1","Player2"},
{"Player2","Tie","Player1"},
{"Player1","Player2","Tie"}
};
int main()
{
map<string,int> pno;
pno["Rock"] = 0;
pno["Scissors"] = 1;
pno["Paper"] = 2;
int n;
cin>>n;
string p1,p2;
for(int i=1;i<=n;i++){
cin>>p1>>p2;
cout<<ans[pno[p1]][pno[p2]]<<endl;
}
return 0;
}
其实还可以直接借助map来记录对战结果:
#include<iostream>
#include<map>
using namespace std;
int main()
{
//记录对战结果
map<string,map<string,string> > ans;
/***********************************************/
//生成记录对战结果的map
//1.选手一出Rock时的对战结果
ans["Rock"]["Rock"] = "Tie"; //选手二出Rock,战平
ans["Rock"]["Scissors"] = "Player1"; //选手二出Scissors,选手一胜出
ans["Rock"]["Paper"] = "Player2"; //选手二出Paper,选手二胜出
//2.选手一出Scissors时的对战结果
ans["Scissors"]["Rock"] = "Player2";
ans["Scissors"]["Scissors"] = "Tie";
ans["Scissors"]["Paper"] = "Player1";
//3.选手一出Paper时的对战结果
ans["Paper"]["Rock"] = "Player1";
ans["Paper"]["Scissors"] = "Player2";
ans["Paper"]["Paper"] = "Tie";
/***********************************************/
int n;
string p1,p2;
cin>>n;
for(int i=1;i<=n;i++){
cin>>p1>>p2;
cout<<ans[p1][p2]<<endl;
}
return 0;
}
如果使用C++11及更高的C++版本,还提供了初始化map的语句,例如:
map<string,int> pno { {"Rock",0},{"Scissors",1},{"Paper",2} };
map<int,string> test { {0,"Rock"},{1,"Scissors"},{2,"Paper"} };
那么,上面的程序可以通过初始化map语句进一步简化 (C++11及更高版本C++。如果使用Dev C++,需要在编译环境中启用C++11,具体方法可以自行百度) :
#include<iostream>
#include<map>
using namespace std;
int main()
{
//记录对战结果
map<string,map<string,string> > ans {
{"Rock",{{"Rock","Tie"},{"Scissors","Player1"},{"Paper","Player2"}}},
{"Scissors",{{"Rock","Player2"},{"Scissors","Tie"},{"Paper","Player1"}}},
{"Paper",{{"Rock","Player1"},{"Scissors","Player2"},{"Paper","Tie"}}},
};
int n;
string p1,p2;
cin>>n;
for(int i=1;i<=n;i++){
cin>>p1>>p2;
cout<<ans[p1][p2]<<endl;
}
return 0;
}
4.寻找特殊单词
寻找一组单词中的特殊单词。特殊单词的定义:如果组内的一个单词经过其任意字符大小写转换、任意两个字符交换位置后都不能变成这组单词中的其他单词,就可以称这个单词是这组单词的特殊单词。
输入样例:
Be BEE EEB Eb B tend a Dnte BeE eBe
输出样例:
a B
这里有一个难点,那就是如何判断一个单词经过任意字符大小写转换、任意两个字符交换位置后能否变成其它单词,如果要去细究每种变化情况,并考虑到每种变化情况还要和其它单词比较,这样太过于复杂了,并且效率非常低下。
这里可以换一个思路,我们想办法把单词“标准化”:先全部转换成小写(或大写),然后再将单词内部的字符排序,结果是一个新的单词。如果两个单词执行“标准话”后的单词相同,那么这两个单词肯定可以通过上述的方式相互转换。可以使用map来记录每一个不同的“标准化”后的单词对应的所有原单词:
#include<iostream>
#include<string>
#include<vector>
#include<map>
#include<algorithm>
using namespace std;
//记录每个标准化单词的原始单词
map<string,vector<string> > counts;
string one,standard;
int main()
{
while(cin>>one){
standard = one;
/***********************************************************/
//输入的单词标准化:所有字符先全部转换成大写,然后排序
//全部转成大写
for(size_t i=0;i<standard.size();i++){
if(standard[i]>='a' && standard[i]<='z') standard[i] -= 'a'-'A';
}
//排序
sort(standard.begin(), standard.end());
/***********************************************************/
//添加
counts[standard].push_back(one);
}
//使用迭代器遍历map
for(auto iter=counts.begin();iter != counts.end();++iter){
if(iter->second.size()==1) cout<<iter->second[0]<<endl;
}
return 0;
}
同样留一个思考问题:上面的程序能否保证找出的特殊单词按照原文出现的顺序输出?